Recurrent Neural Networks: Visualizing Hidden Activations
/ 4 min read
Last Updated:Introduction
In this blog post, we’ll delve into Recurrent Neural Networks (RNNs) by solving a simple prediction task and visualizing the hidden unit activations. This approach will provide insights into how the network learns and represents information internally.
The Problem
Our task is to train an RNN to predict the next character in a sequence of the form or , where is a positive integer. Specifically:
- For : The sequence consists of ‘a’s followed by ‘b’s.
- For : The sequence consists of ‘a’s, followed by ‘b’s, followed by ‘c’s.
In these sequences, all characters after the last ‘a’ are deterministic. For example, given the input “aaab”, the network should predict the next character as ‘b’ with probability 1.
Recurrent Neural Networks: A Brief Overview
Recurrent Neural Networks are a class of artificial neural networks designed to process sequential data. Unlike feedforward networks, RNNs have connections that form directed cycles, allowing them to maintain an internal state or “memory”. This makes them particularly well-suited for tasks involving time series or sequence prediction.
The basic structure of an RNN can be described by the following equations:
Where:
- is the input at time step
- is the hidden state at time step
- is the output at time step
- , , and are weight matrices
- and are bias vectors
- and are activation functions (typically non-linear)
This recursive formulation allows RNNs to process sequences of arbitrary length, making them ideal for our character prediction task.
Simple Recurrent Network
For the problem, we construct an SRN with 2 input units, 2 hidden units, and 2 output units. After training for 100,000 epochs, we achieve an impressively low error rate of 0.0129. Let’s visualize the hidden activations to understand how the network solves this task:
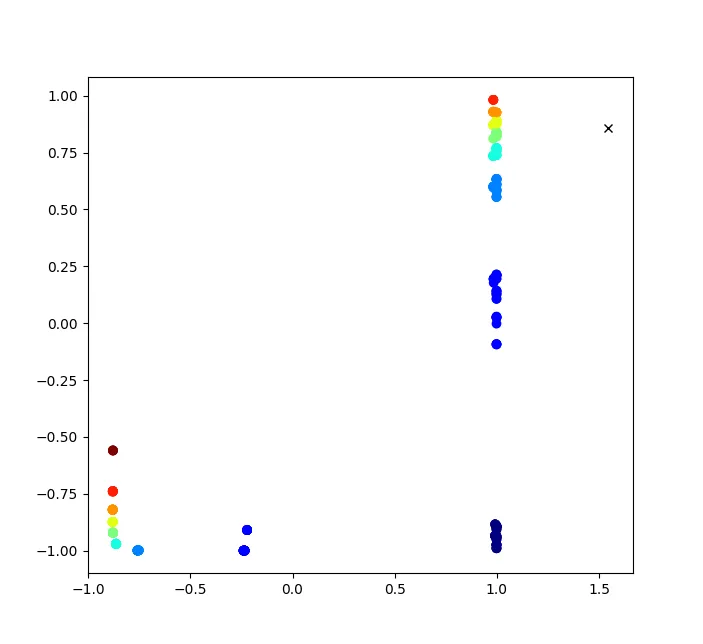
The activation space reveals two distinct clusters:
- A cluster parallel to the x-axis, corresponding to ‘a’ characters.
- A cluster at the top of the plot, corresponding to ‘b’ characters.
These clusters serve dual purposes:
- They distinguish between ‘a’ and ‘b’ classes.
- Variations within each cluster encode count information.
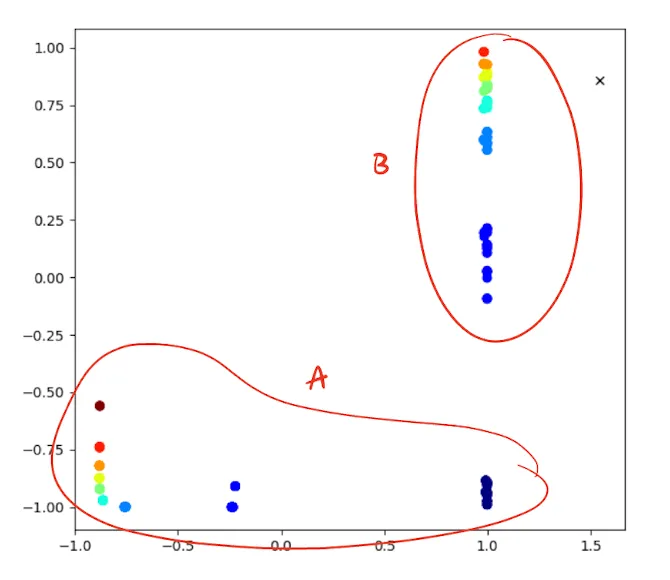
We can interpret the activations as follows:
- For ‘a’ characters: A more negative x-value indicates a higher count of ‘a’s seen so far. Interestingly, after the 4th ‘a’, the trend shifts upward instead of continuing left.
- For ‘b’ characters: A more positive y-value indicates a higher count of ‘b’s expected to follow.
As the network processes a string of ‘a’s and ‘b’s, it traverses this activation space in a clockwise manner. Notably, all deterministically predictable entries (the first ‘a’ after a sequence of ‘b’s and all ‘b’ entries) roughly align along the line x = 1. Other points can only be predicted probabilistically.
Simple Recurrent Network
Extending our problem to three dimensions, we now consider sequences of the form . Our network architecture expands to 3 input units, 3 hidden units, and 3 output units. After 200,000 epochs of training, we achieve an error rate of 0.0083.
Let’s visualize the 3-dimensional hidden activations:
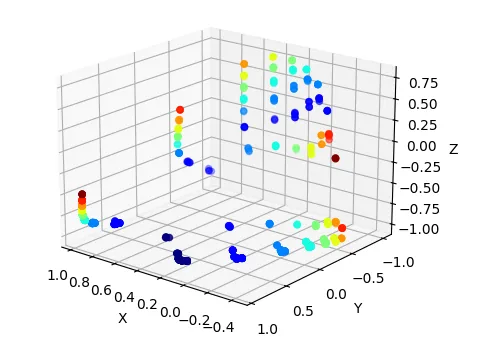
Remarkably, many insights from the 2D case generalize to 3D. We observe four main clusters:
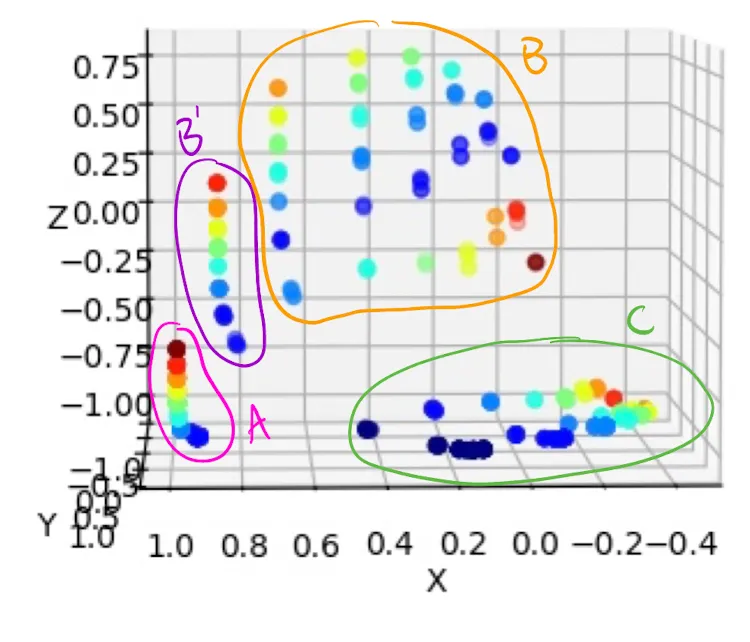
- Cluster A: Contains non-deterministic ‘a’s.
- Cluster B’: A transition state containing the first deterministic ‘b’ in a sequence.
- Cluster B: Approximately aligns with Y = -1, containing remaining ‘b’s and the transition ‘c’.
- Cluster C: Approximately aligns with Z = -1, containing remaining ‘c’s and the transition ‘a’.
As in the 2D case, we can conceptually separate deterministic and non-deterministic points. The network traverses this 3D space in an organized manner: A → B’ → B → C → A.
Each cluster acts as a counter, with different positions within a cluster representing the number of remaining characters of that type. For a clearer view of this counting mechanism:
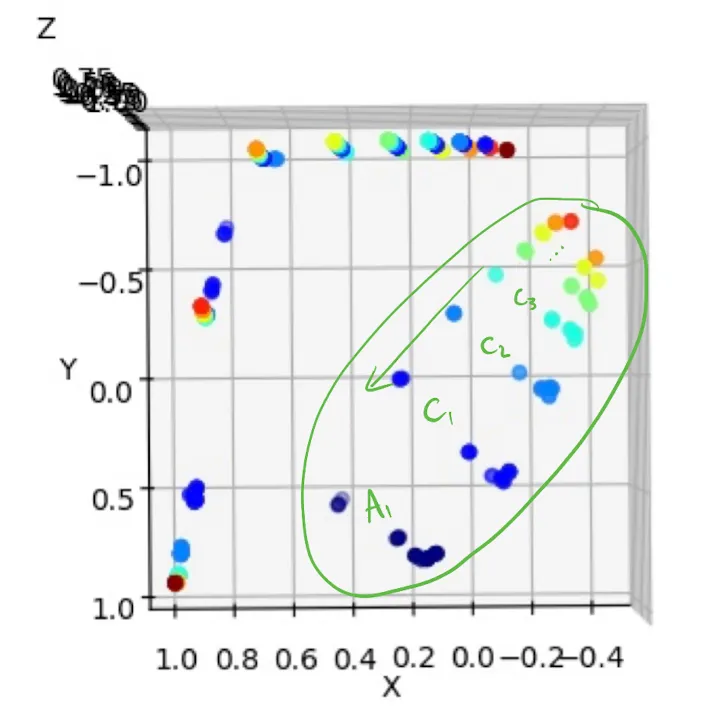
Here, represents the end of a ‘c’ sequence and the first ‘a’ of the next sequence, while indicates n ‘c’s remaining. This monotonic counting vector is present in all clusters, and viewing from the perspective of the previous figure, we move through all clusters in a clockwise fashion.
Conclusion
By visualizing the hidden activations of RNNs trained on and sequences, we’ve gained valuable insights into how these networks internally represent and process sequential information. The emergent structure in the activation space demonstrates the network’s ability to learn both classification and counting tasks simultaneously, showcasing the power and interpretability of RNNs in sequence prediction tasks.