Introduction
In today’s blog post, I explore and explain a reinforcement algorithm called Q-learning, in the context of teaching an agent to control traffic signals in Python.
Q Reinforcement Learning
In reinforcement learning, we have an agent (our AI), a set of states (a way of describing the environment in which the agent will act) and a set of actions that the agent can take. The agent’s objective is to maximise its reward function, which is chosen such that the agent is encouraged to behave in a desired manner.
In our case, our agent’s objective is to maximise the discounted, cumulative reward . We set , to ensure that the sum converges. In Q-learning, we are interested in exploring some function , which describes the ‘quality’ of a state action pair. In Deep Q-Learning, we make use a neural network as a way of approximating this non-linear function.
In reinforcement learning, one has to decide how much time the agent should spend exploring the environment before starting to exploit the knowledge it has gained. This is controled through a parameter called . Initially, is set high to encourage exploration, and it gradually decays over time to favor exploitation as the agent learns according to another parameter called -decay.
SUMO Environment
Our environment is a simple intersection created in SUMO (Simulation of Urban MObility). SUMO is an open-source, highly portable, microscopic and continuous multi-modal traffic simulation package designed to handle large networks. In our simulation:
- Green cars arrive according to a Poisson process with
- Blue cars arrive at a more intense linear rate
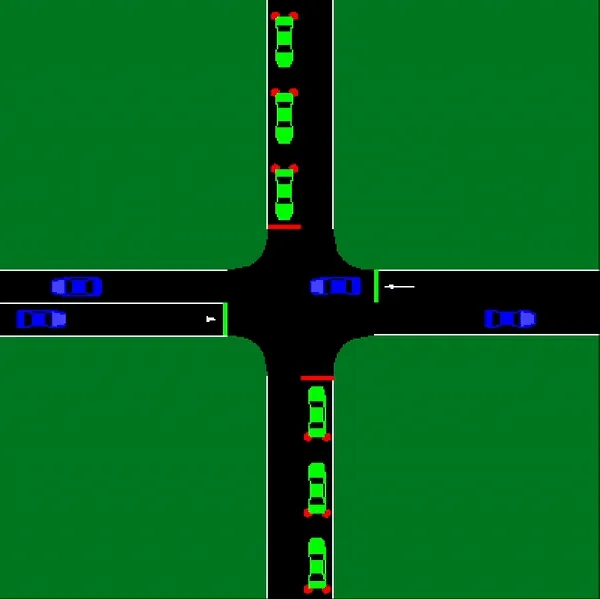
The above demonstration shows the traffic lights operating on an evenly-spaced timer, similar to many real-world implementations. It’s evident that there’s room for efficiency improvements.
To interact with this SUMO environment and apply our deep reinforcement learning approach, we’ll be using two key packages:
-
SUMO-RL: This provides a reinforcement learning interface for SUMO, allowing us to easily apply RL algorithms to our traffic signal control scenario.
-
Gymnasium: Formerly known as OpenAI Gym, this toolkit offers a standardized API for reinforcement learning tasks. It will help us define our environment, state space, and action space in a format compatible with our DQN algorithm.
Training Our Agent
Our task is to train a DQN to optimize traffic signal control in an urban environment. Specifically, we aim to:
- Minimize overall wait time for vehicles at intersections.
- Maximize traffic throughput across the network.
- Adapt signal timings in real-time based on current traffic conditions.
I used PyTorch for the neural network component of the architecture. Given the relatively simple state-action space of this problem, our neural network takes the following form:
class DQN(torch.nn.Module): def __init__(self, state_size, action_size): super(DQN, self).__init__() self.fc1 = torch.nn.Linear(state_size, 36) self.fc2 = torch.nn.Linear(36, 24) self.fc3 = torch.nn.Linear(24, action_size)
def forward(self, x): x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) return self.fc3(x)In this implementation, I use the default SUMO-rl reward function. I also found that the default was decaying too quickly, leading to premature convergence to suboptimal policies. To address this, I increased the -decay rate to 0.9998. This slower decay allows the agent to explore more thoroughly in the early stages of training, resulting in more robust learning and better long-term performance.
Let’s examine the results from training:
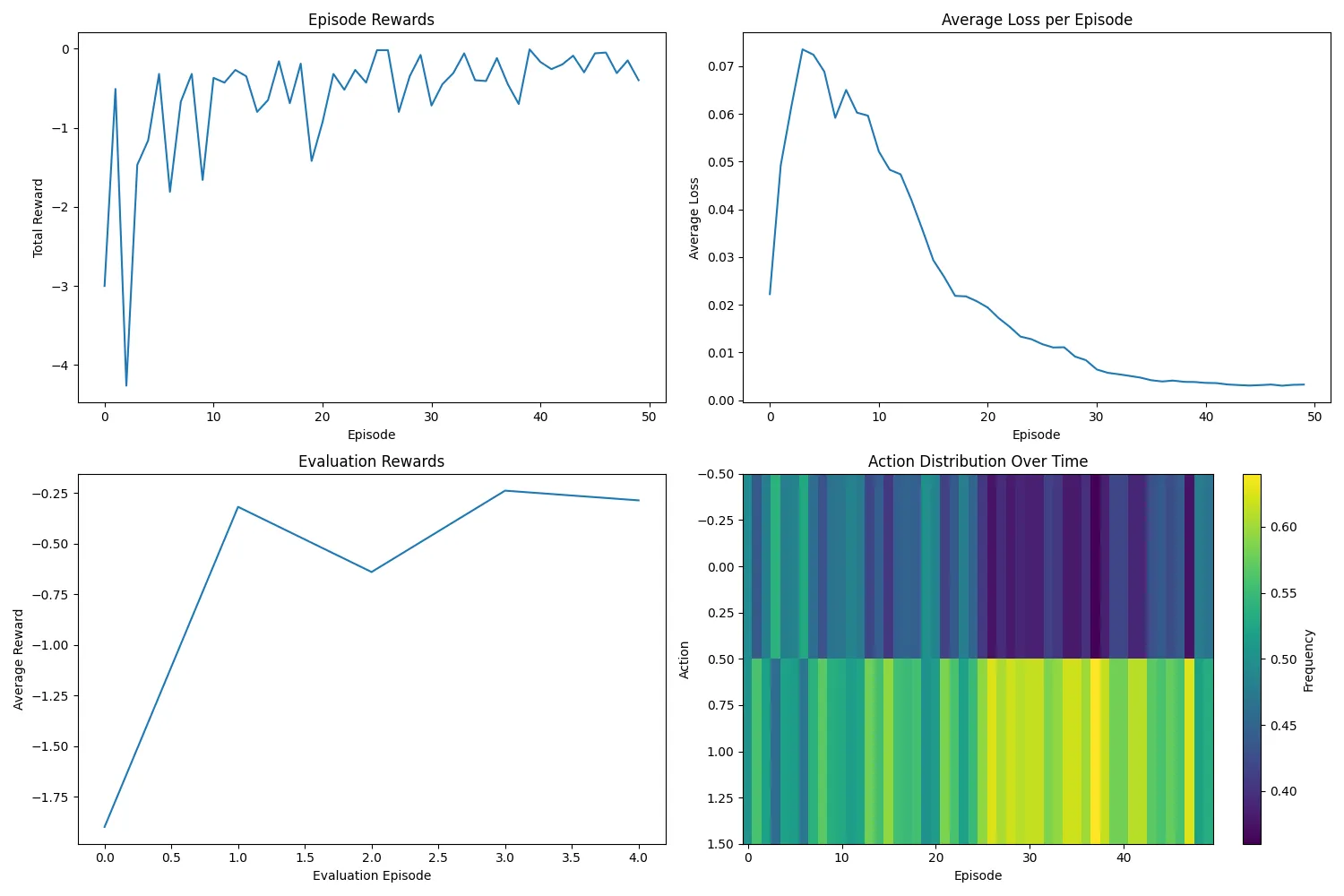
The plots show:
- The loss has roughly stabilized, suggesting our neural network has effectively learned the Q-values.
- Episode rewards are improving over time.
- The action distribution demonstrates that the network is learning the differences in traffic frequency between the two roads.
Finally, let’s take a look at the results of our trained network in action:
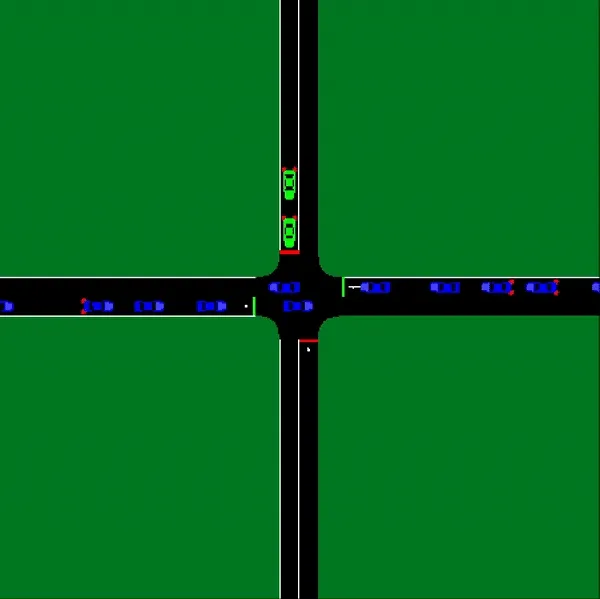
Notice how the trained network optimizes signal timing:
- It doesn’t allow the green car signal to be on when there are no cars.
- When the green car signal is on, it’s only for a short period, adapting to the lower frequency of green cars.
These results demonstrate the advantage our DQN has over the traditional fixed-time approach in managing traffic signals efficiently.